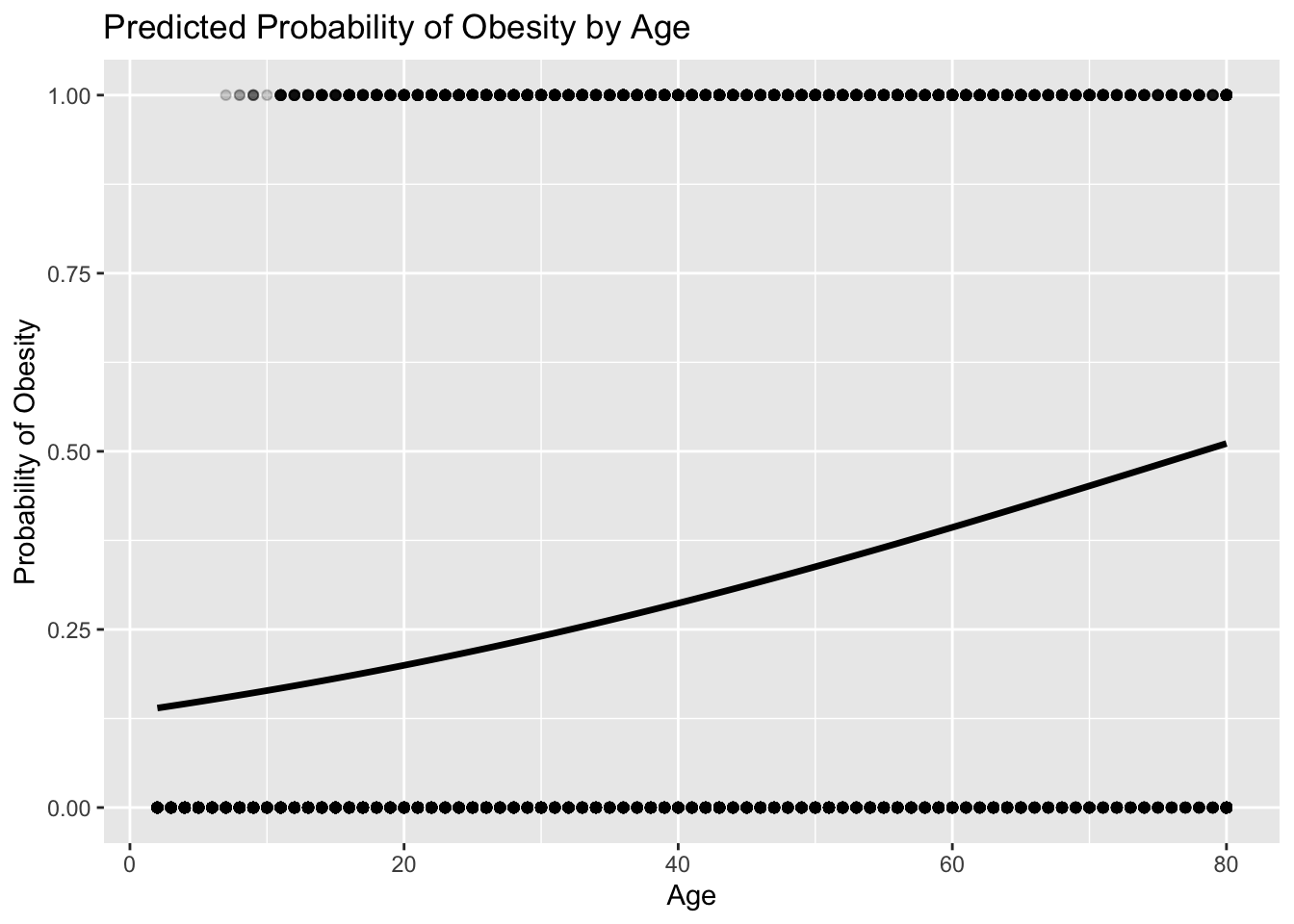
Our example research question: Is obesity associated with age?
model <-glm(high_bmi ~ Age, data = df, family = binomial)summary(model)
Call:
glm(formula = high_bmi ~ Age, family = binomial, data = df)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.865791 0.051335 -36.34 <2e-16 ***
Age 0.023872 0.001084 22.01 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 11552 on 9633 degrees of freedom
Residual deviance: 11040 on 9632 degrees of freedom
AIC: 11044
Number of Fisher Scoring iterations: 4
What Is Happening Here?
glm() fits a generalized linear model.
family = binomial specifies a binary outcome.
The model estimates log-odds, not probabilities.
The coefficient for Age is on the log-odds scale.
It must be transformed before interpretation.
4. Convert Coefficients to Odds Ratios
exp(coef(model))
(Intercept) Age
0.1547737 1.0241594
Interpretation:
Each additional year of age is associated with a 2% increase in the odds of obesity.
Interpretation Rules
OR = 1 → No association
OR > 1 → Increased odds
OR < 1 → Decreased odds
Examples:
OR = 1.25 → 25% higher odds
OR = 0.80 → 20% lower odds
5. Confidence Intervals for Odds Ratios
exp(confint(model))
Waiting for profiling to be done...
2.5 % 97.5 %
(Intercept) 0.1398656 0.1710458
Age 1.0219920 1.0263459
Interpretation framework:
Each one-year increase in age was associated with a ___-fold increase in odds of obesity (95% CI: lower to upper).
How to Interpret Confidence Intervals
If the CI includes 1 → not statistically significant
If the CI does not include 1 → statistically significant
CIs communicate magnitude and uncertainty
In public health research, effect size and uncertainty matter more than p-values alone.
6. Predicted Probabilities
Odds ratios can be abstract.
Public health audiences often understand probabilities better.