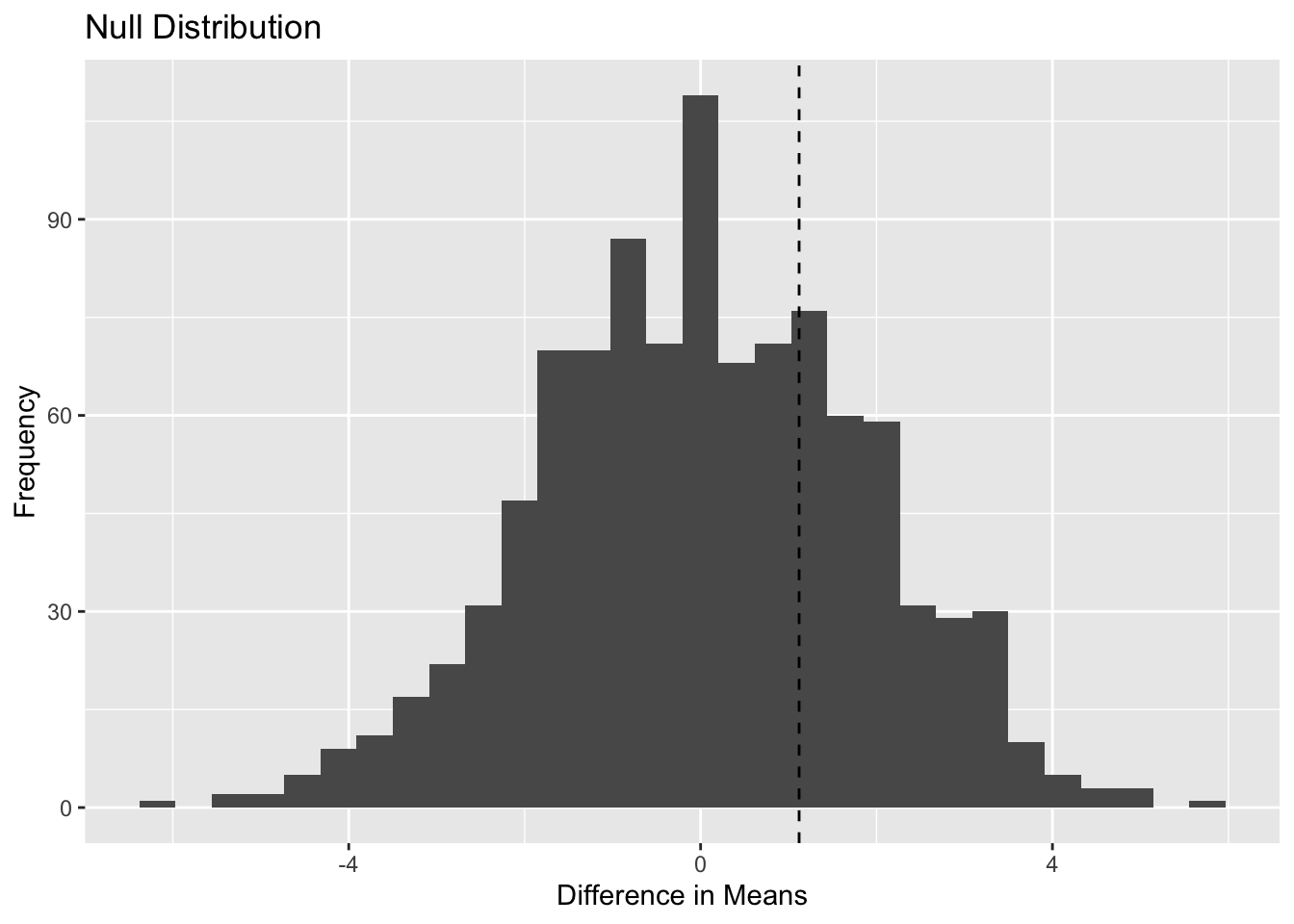
In this activity, you will use simulation to understand hypothesis testing and p-values.
Scenario:
A researcher wants to know whether a new intervention changes an outcome compared to a control group.
Step 1: Set Up the Data
library(tidyverse)
Warning: package 'dplyr' was built under R version 4.5.1
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
set.seed(123)group <-rep(c("Control", "Intervention"), each =50)outcome <-rnorm(100, mean =50, sd =10)df <-tibble(group, outcome)df
# A tibble: 100 × 2
group outcome
<chr> <dbl>
1 Control 44.4
2 Control 47.7
3 Control 65.6
4 Control 50.7
5 Control 51.3
6 Control 67.2
7 Control 54.6
8 Control 37.3
9 Control 43.1
10 Control 45.5
# ℹ 90 more rows