Simulation-First Thinking, P-values, and Biomedical Interpretation
Overview
Hypothesis testing allows us to evaluate whether observed patterns in data are likely due to chance or reflect a real underlying relationship.
In this lesson, we take a simulation-first approach to hypothesis testing, emphasizing intuition, interpretation, and real-world biomedical framing rather than memorizing formulas.
Learning Objectives
By the end of this lesson, students will be able to:
Explain the logic of hypothesis testing using simulation
Define null and alternative hypotheses in public health contexts
Interpret p-values as measures of evidence strength
Avoid common misinterpretations of p-values
Apply hypothesis testing to real-world biomedical questions
Connect hypothesis testing to regression inference
Assigned Readings
OpenIntro Biostatistics, Chapter 5
Statistical Inference via Data Science, Chapter 10: Inference for Regression
What Is Hypothesis Testing?
Hypothesis testing is a framework used to evaluate whether observed data are consistent with a specific claim about a population.
We compare:
what we observed in our data
what we would expect under a null hypothesis
Null and Alternative Hypotheses
The null hypothesis (H₀) represents no effect or no association.
The alternative hypothesis (H₁ or Hₐ) represents a meaningful effect or association.
Example (Public Health)
H₀: There is no difference in screening rates between groups
Hₐ: There is a difference in screening rates between groups
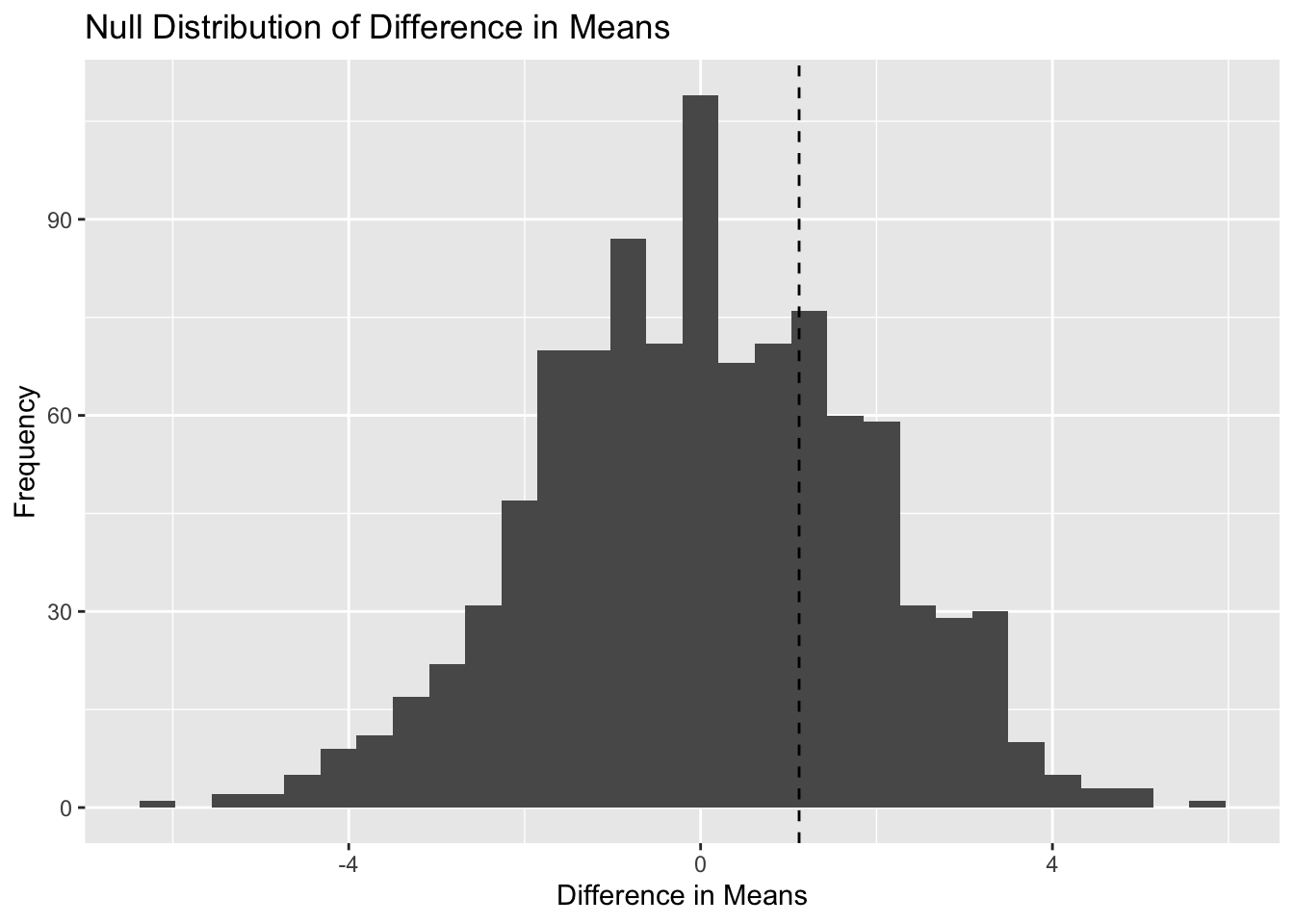
Simulation-First Thinking
Instead of jumping straight to formulas, we ask:
What would our data look like if the null hypothesis were true?
We then simulate many datasets under the null and compare our observed statistic to that distribution.
Example: Simulating a Null Distribution
library(tidyverse)
Warning: package 'dplyr' was built under R version 4.5.1
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
set.seed(123)# Create two groups with no real differencegroup <-rep(c("A", "B"), each =50)outcome <-rnorm(100, mean =50, sd =10)df <-tibble(group, outcome)# Observed difference in meansobs_diff <- df |>group_by(group) |>summarise(mean_val =mean(outcome)) |>summarise(diff =diff(mean_val)) |>pull(diff)obs_diff