Confidence intervals are one of the most important tools in statistical inference. They allow us to move beyond a single estimate and instead communicate a range of plausible values for a population parameter.
In this lesson, we focus less on calculation and more on interpretation, logic, and communication, which are essential skills in public health and data science.
Learning Objectives
By the end of this lesson, students will be able to:
Explain the logic behind confidence intervals
Interpret confidence intervals in plain language
Distinguish correct vs incorrect interpretations
Communicate uncertainty effectively in public health contexts
Connect confidence intervals to hypothesis testing concepts
Assigned Readings
OpenIntro Biostatistics, Chapter 4
Statistical Inference via Data Science, Chapter 9: Hypothesis Testing
What Is a Confidence Interval?
A confidence interval (CI) provides a range of plausible values for a population parameter.
Instead of reporting:
“The mean BMI is 27.3”
we report:
“The mean BMI is 27.3 (95% CI: 26.5 to 28.1)”
Interval Logic
Confidence intervals are built on three key components:
Estimate (sample statistic)
Standard Error (variability)
Critical Value (confidence level)
Mathematically:
\[
\text{Estimate} \pm \text{Critical Value} \times SE
\]
Why Intervals Matter
A single number does not show uncertainty.
Confidence intervals:
show precision of estimates
reflect sampling variability
provide context for decision-making
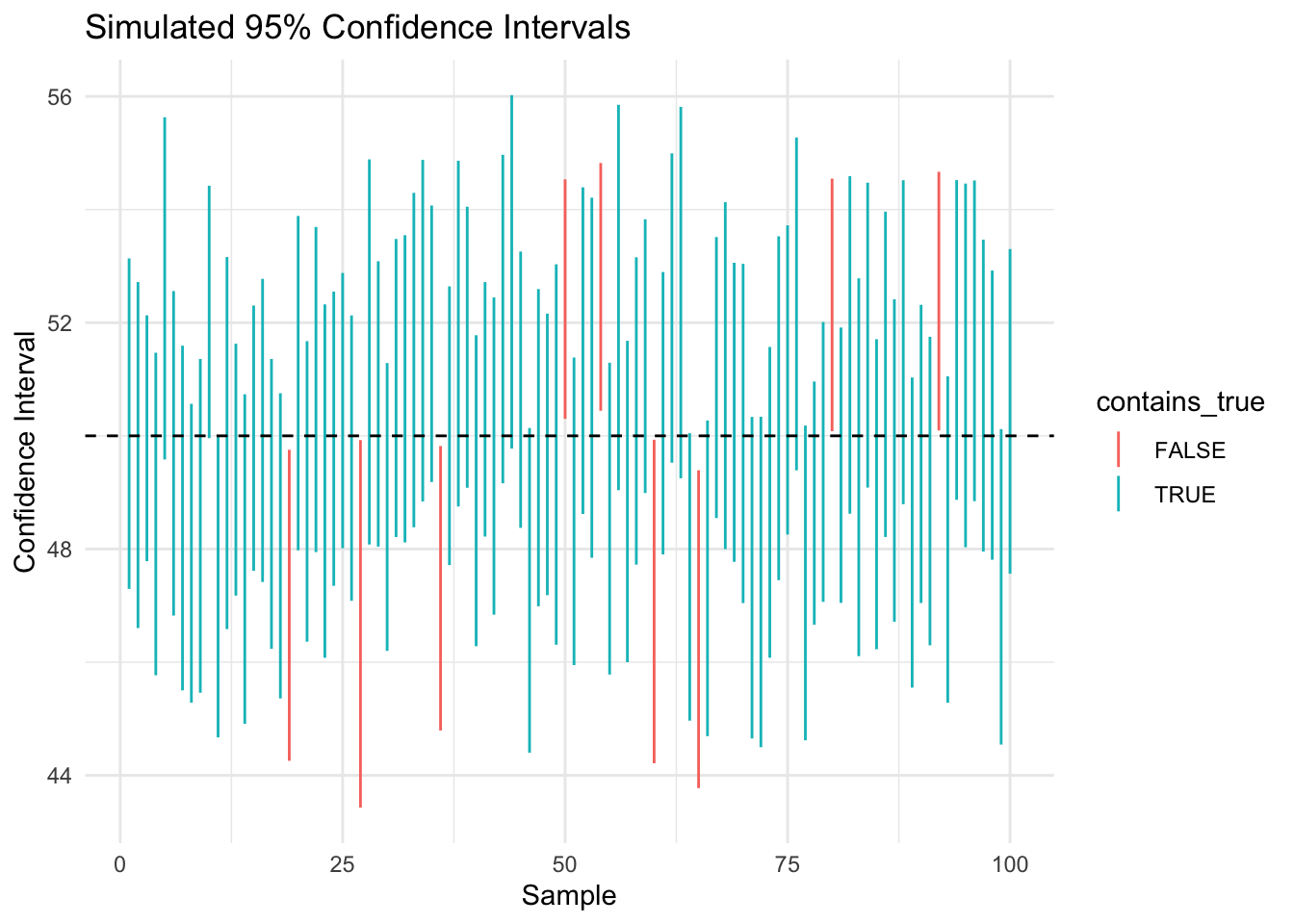
Visualizing Uncertainty
library(tidyverse)
Warning: package 'dplyr' was built under R version 4.5.1
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
set.seed(123)# Simulate many confidence intervalstrue_mean <-50population <-rnorm(10000, mean = true_mean, sd =10)ci_sim <-replicate(100, { samp <-sample(population, 50) m <-mean(samp) se <-sd(samp)/sqrt(50) lower <- m -1.96* se upper <- m +1.96* sec(lower, upper)})ci_df <-as.data.frame(t(ci_sim))names(ci_df) <-c("lower", "upper")ci_df$id <-1:nrow(ci_df)ci_df$contains_true <- ci_df$lower <= true_mean & ci_df$upper >= true_meanhead(ci_df)